
There’s a moment that a lot of knowledge workers describe in almost identical terms. You’re deep in a task, drafting a strategy memo or synthesizing research for a board presentation, and you realize you’ve spent the last forty minutes doing something a reasonably intelligent system could have handled in four seconds. Not the thinking part. The gathering, formatting, cross-referencing, reformatting part. The cognitive janitorial work that somehow still eats a quarter of your Tuesday.
For decades, we called this “the job.” Now, increasingly, we’re calling it unnecessary.
Something genuinely significant is happening to how knowledge work gets done, and it’s not the story most technology coverage tells. The headlines fixate on chatbots answering trivia, AI art generating controversy, or the latest model benchmark leapfrogging the previous one. What those stories miss is the quieter, more consequential shift: AI is not just becoming a tool you pick up occasionally, like a calculator or a spell-checker. For a growing number of professionals, it is becoming the operating system through which work itself flows.
That phrase, AI as operating system, is worth sitting with for a moment. An operating system doesn’t do your work for you. It manages resources, coordinates between applications, handles the low-level operations so the higher-level programs can run efficiently. What’s emerging now, through a combination of capable frontier models, agentic frameworks, integrations, and workflow redesign, is something structurally similar for cognitive labor. A layer beneath the work that handles the mechanics, freeing the human layer to operate at a higher level of abstraction.
This article is about what that shift actually looks like in practice, why it’s further along than most organizations realize, what the genuine friction points are, and what it means to be a knowledge worker in 2025 and beyond. Not the utopian version. Not the dystopian one either. The complicated, genuinely interesting real one.
Let’s go back to how we’ve historically thought about productivity software. The metaphor that shaped the last thirty years of enterprise technology was the desktop. Files lived in folders. Applications were discrete. You opened Word to write, Excel to calculate, Outlook to communicate. Work was a series of handoffs between siloed tools, and your brain was the integration layer: the thing that read the email, opened the spreadsheet, extracted the relevant numbers, pasted them into the document, and sent the summary back.

This model worked tolerably well when information volumes were manageable and the tools themselves were genuinely hard to build. But somewhere around the mid-2010s, it started to buckle. The number of applications the average knowledge worker touches in a day exploded. Research from productivity analytics company Productive found that large enterprises use somewhere north of 200 SaaS applications. Most employees interact with a meaningful fraction of them daily. Every tool has its own interface, its own data model, its own notification system. The cognitive overhead of operating the tools began competing seriously with the cognitive work the tools were supposed to support.
Search became the coping mechanism. Can’t remember where something lives? Search for it. Don’t know the formula? Search. Need a template? Search, download, adapt. Knowledge workers became, in large part, expert navigators of information retrieval systems. A significant portion of what made someone “good at their job” was actually competence at finding, filtering, and reformatting information across fragmented systems.
When people first encountered tools like ChatGPT, many framed the use case as “asking questions and getting answers.” A smarter search engine. And for a lot of casual users, that framing has stuck. But it dramatically undersells the structural shift.
The more precise framing is this: large language models are, at their core, universal interfaces. They can take in information in nearly any form, whether a messy email thread, a PDF contract, a table of sales data, or a rough spoken brief, and produce structured, reasoned output calibrated to what you actually need. That’s not a better search engine. That’s a different abstraction layer entirely.
Think about what a senior analyst or a skilled executive assistant actually does. They read incoming information from many sources, understand context and priority, synthesize what’s relevant, draft outputs in the appropriate register, flag what needs human attention, and remember what’s been decided before. That bundle of capabilities, intake and synthesis and memory and output and escalation, is precisely what mature AI integrations are starting to approximate. Not perfectly. Not without failure modes worth taking seriously. But at a level of competence that is changing the math on how work gets organized.
Here’s the distinction that gets lost most often in discussions about AI productivity: the difference between using AI as a tool and using it as a layer.
Using AI as a tool means you have a task, you open a chat interface, you ask a question or request a draft, you get output, you close the interface and go back to your normal workflow. It’s additive. Helpful. But structurally, your workflow hasn’t changed. You’ve just added a capable assistant you can consult on demand.
Using AI as a layer means the AI is woven into the workflow itself. Documents are being drafted in environments where AI is an active collaborator from the first keystroke. Research is routed through models before it reaches the analyst. Customer emails are triaged, summarized, and pre-responded before a human reviews them. Meetings are transcribed, summarized, and turned into action items automatically. The AI isn’t something you turn to; it’s something you’re always working through.
The difference matters enormously. Tool usage improves individual output at the margins. Layer integration restructures what the job actually is.
When I use the phrase “AI operating system,” I’m not referring to a specific product, though several companies are actively trying to build exactly that. I’m describing a pattern of integration that’s assembling itself across the modern knowledge workplace, sometimes deliberately, sometimes by accident, through the adoption of enough overlapping AI capabilities that something OS-like emerges.
There are five functional layers to this emerging system, and each one is worth understanding on its own terms.
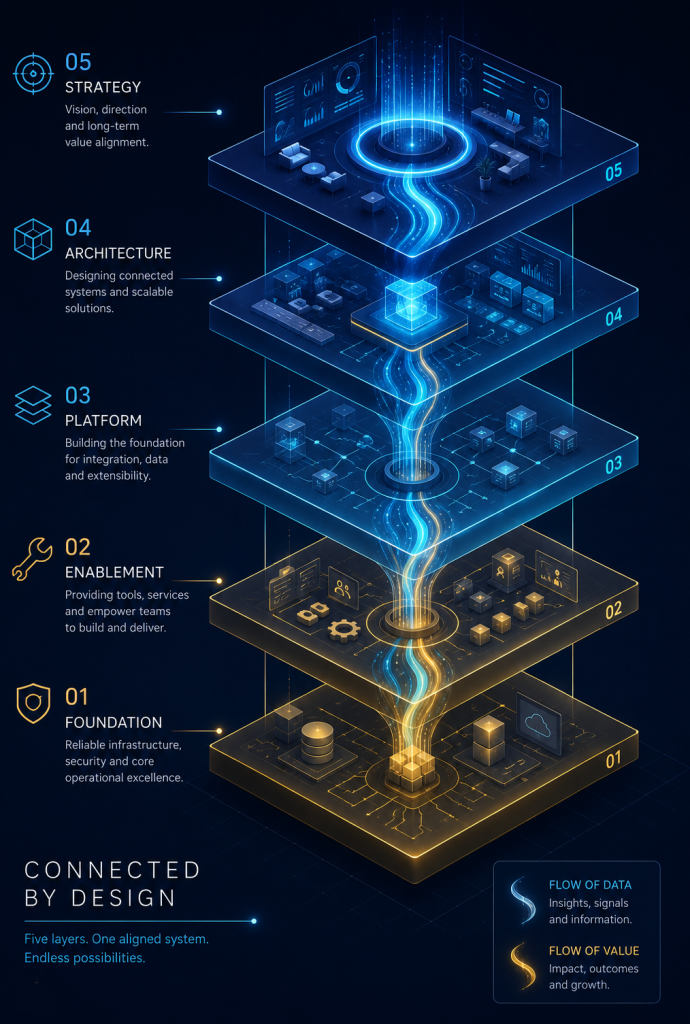
5 Layers of an AI Operating System
The first layer is about capture. One of the chronic inefficiencies of knowledge work is the lossy translation between what happens and what gets recorded. Meetings produce decisions that don’t make it into notes. Conversations happen in Slack that never connect to the project management system. Ideas occur in the shower and dissolve by the time you open a doc.
AI-powered capture tools are attacking this problem from multiple directions. Transcription and summarization products like Otter.ai, Fireflies, and the native capabilities being built into Zoom and Microsoft Teams are making it trivial to convert spoken conversation into structured text. But the more interesting development is what happens after transcription: models that can extract not just what was said, but what was decided, what was committed to, what is unresolved, and who is responsible for what.
Notion’s AI features do something adjacent to this for written documents. So does the increasingly capable document intelligence in tools like Microsoft Copilot. The ambient input layer is essentially building a continuous, AI-mediated record of knowledge work as it happens, in a form that’s actually quarriable and actionable later.
The catch, and it’s a real one, is that capturing everything doesn’t mean understanding everything. Context is brutally hard to encode. The reason a particular decision was made in a meeting, the political dynamics, the constraints that weren’t stated aloud, the history between the two people who seemed to agree but didn’t really, that stuff doesn’t transcribe. The ambient input layer is genuinely useful, but it creates a risk of false confidence: the illusion that because the meeting is documented, it’s understood.
The best implementations of this layer treat AI output as a starting point for human review, not a final record. A summary that a team member glances at and annotates in thirty seconds captures the machine’s efficiency and the human’s contextual knowledge. That hybrid is where the real value sits.
If the input layer is about capturing what happens, the memory layer is about making sure the right prior knowledge is accessible when it’s needed. This is where AI is solving a problem that has gotten quietly catastrophic in most organizations: institutional amnesia.
Ask anyone who’s been at a mid-to-large company for more than three years about the experience of onboarding a new team member. The new person asks why a certain system works the way it does, or why a particular client relationship is structured a certain way, and the honest answer is: “there’s a document somewhere, or maybe it was a decision made in a meeting in 2021, but the person who knows is now at another company.” Knowledge walks out the door with people. Processes accumulate invisible dependencies on undocumented context.
Retrieval-augmented generation, or RAG, is the technical approach that’s making real inroads here. The basic idea is that you give a language model access to a curated store of your organization’s documents, communications, and records, and it can pull relevant context when answering questions or generating content. Instead of a model relying solely on what it learned during training, it’s reaching into your actual institutional knowledge base.
Products like Glean, Guru, and the enterprise search layer of Microsoft 365 Copilot are essentially RAG systems built for organizations. Ask them “what’s our standard approach to enterprise procurement contracts?” and they’ll search your actual documentation, find the relevant policies and past examples, and synthesize an answer grounded in your specific organizational reality, not generic training data.
One example worth examining is how some professional services firms are deploying internal knowledge systems. Consulting and law firms, whose competitive advantage is literally the quality and accessibility of their collective expertise, have been early and serious adopters. The use case is almost embarrassingly obvious in retrospect: you have thousands of previous client engagements, briefs, analyses, and memos sitting in document management systems, largely inaccessible except through painful manual search. You have new associates spending days looking for precedents that a senior partner would know in five seconds from memory.
A well-built RAG system effectively democratizes that senior partner’s memory. A first-year associate can ask “have we done any work involving cross-border IP licensing for European pharmaceutical clients in the last five years?” and get a synthesized answer with source documents in seconds rather than days. The knowledge is still human-generated. The access has been fundamentally transformed.
There’s an irony embedded in the story of knowledge work over the last decade. We built incredible tools for communication and collaboration, and those tools proceeded to consume the cognitive bandwidth required to do the actual work they were supposed to support. Email was supposed to make communication more efficient; instead it created an expectation of perpetual availability that colonized the workday. Slack was supposed to reduce email; it created a new ambient interruption layer on top of it.
The result was a workplace where the scarcest resource wasn’t information, processing power, or even talent. It was sustained human attention. Cal Newport has written about this extensively, but you don’t need to have read his books to feel it viscerally. Most knowledge workers know the experience of sitting down to do something genuinely hard, a complex analysis, a difficult piece of writing, a thorny strategic question, and finding that between notifications, context switches, and the background anxiety of an overflowing inbox, that deep focused state is nearly impossible to reach and maintain.
Here’s something that doesn’t get said enough: properly implemented AI workflow integration can return attention, not just redirect it.
Consider what a well-configured AI triage system does for email. Instead of every message hitting your inbox with equal visual weight and demanding roughly equal cognitive engagement to sort through, an AI layer pre-reads, categorizes, flags genuinely urgent items, drafts responses to routine messages for your approval, and summarizes threads you’ve been CC’d on but don’t need to act on. The mechanical scanning and sorting that previously consumed twenty minutes at the top of every hour instead happens continuously in the background, and you engage only with the small percentage of messages that actually require your judgment.
That’s not a minor efficiency gain. That’s a structural change in the relationship between communication overhead and cognitive availability. And it compounds: when the tax on attention is lower, the quality of the deep work that fills the freed-up space tends to rise with it.
There’s a meaningful difference between an AI that responds to your questions and an AI that takes actions on your behalf. For the first few years of the modern AI wave, almost everything consumers and businesses interacted with fell into the first category. You typed something in, you got something back. The interaction was fundamentally conversational, even when the output was sophisticated.
That’s changing, and the change is significant enough that it deserves its own section.
Agentic AI refers to systems that can pursue multi-step goals autonomously, using tools, making decisions along the way, and completing tasks that would otherwise require sustained human attention across multiple applications and contexts. Instead of telling you how to book a flight, an agent books the flight. Instead of explaining how to pull competitor pricing data from three sources and format it into a comparison table, an agent does the pulling, the formatting, and drops the finished table into your shared drive.
The practical difference between a capable language model and an agentic system is roughly the difference between a brilliant advisor who gives you great advice and a brilliant colleague who also executes. Both are valuable. One changes your workload in a fundamentally different way.
It’s worth being specific here, because the word “agent” gets thrown around in contexts ranging from genuinely impressive to barely-functional demos. The realistic picture in 2025 is that agents are highly capable within well-defined domains and noticeably fragile when tasks require navigating ambiguity or recovering from unexpected states.
On the capable side: agents can reliably browse the web and synthesize research across many sources. They can write and execute code to transform data, run analyses, and generate visualizations. They can interact with APIs, which means they can read from and write to the tools your organization already uses, your CRM, your project management software, your calendar, your document store. They can chain these capabilities together to complete workflows that would previously have required a human to manually coordinate between four different applications.
Anthropic’s own Claude, when given access to tools through an MCP (Model Context Protocol) setup, can do things like pull open tasks from a project management tool, check calendar availability for the relevant people, draft a scheduling proposal, and send it, without a human touching each step individually. Google’s Gemini has similar agentic capabilities woven into Workspace. Microsoft’s Copilot agents are being deployed inside enterprises to handle everything from IT support ticket triage to contract review workflows.
On the fragile side: agents struggle when they encounter an unexpected state mid-task and have to decide whether to proceed, backtrack, or ask for help. They can fail in compounding ways, where a small error in step two produces a confidently wrong output in step six that looks plausible enough that nobody catches it. They have real trouble with tasks where the definition of “done correctly” is highly subjective or context-dependent in ways that weren’t spelled out upfront.
The most productive way to think about agents right now is as highly capable junior staff who are extraordinary at structured execution and genuinely unreliable at exercising judgment in novel situations. You wouldn’t give a brilliant but inexperienced new hire a vague brief and tell them to handle it completely autonomously with no check-ins. You’d give them a clear task with explicit success criteria, access to the tools they need, and a checkpoint before anything consequential goes out the door.
That framing isn’t a criticism of current AI capability. It’s actually a useful guide for deployment. The organizations getting the most out of agentic systems right now are the ones that have been disciplined about defining clear workflows, specifying explicit success conditions, and building human review into the loop at the points where judgment matters most. The ones struggling are often the ones who heard “autonomous” and interpreted it as “unsupervised.”
This is the layer most people have the most direct experience with, because it’s the most visible: AI helping generate the actual work product. Drafts, analyses, presentations, code, reports, proposals. The thing that lands in front of another human bearing your name.
It’s also the layer where the most anxiety tends to cluster, for understandable reasons. There’s something that feels qualitatively different about AI handling input and organization versus AI generating the output that represents your thinking. And that discomfort, when you look at it carefully, points to something worth taking seriously.
The synthesis and output layer is genuinely powerful. A skilled user working with a capable model can produce a first draft of a complex research memo in a fraction of the time it would take to write from scratch. They can generate multiple framings of an argument and evaluate which holds up better. They can translate technical analysis into executive-friendly language, adapt a proposal to a different audience’s priorities, or convert a messy set of notes into a structured document with logical flow. These are real time savings that accumulate into meaningful productivity gains.
But the layer also introduces a subtle trap that the best practitioners are very aware of: the difference between generation and thinking.
Writing, at its best, is not a documentation exercise. It’s a thinking exercise. The act of trying to articulate something clearly, struggling with it, finding the right framing, discovering mid-sentence that your argument has a hole in it, those moments of productive difficulty are where a lot of real intellectual work happens. They’re where you find out whether you actually understand something or just think you do.
When AI handles the generation fluently and quickly, it’s easy to skip that struggle. You get a polished draft that reads well and covers the main points, and you never have to work through the question yourself deeply enough to discover what you don’t know. The output looks like thinking. It may not represent thinking.
The practitioners who use AI output layers most effectively tend to have a discipline around this. They use AI generation to handle structure and first-pass drafting, and then they actually engage with the output critically, rewriting substantially, arguing with it, pushing on the logic, adding the specific knowledge and judgment that the model doesn’t have. They treat the AI draft as scaffolding, not as the building. The scaffolding saves enormous time. But you still have to build.
If you spend time reading about AI in the workplace, you’ll encounter two dominant narratives. One says AI is going to automate everything and knowledge workers should be updating their resumes. The other says AI is overhyped and the productivity gains are illusory and people are just doing the same work with fancier autocomplete. Both of these narratives are wrong in interesting ways, and both are missing the actual friction that’s shaping how AI integration plays out in real organizations.

The first real friction is unglamorous but decisive: most organizations’ data and systems are not in a state that makes serious AI integration straightforward. The AI tools are impressive. The organizational infrastructure they need to connect to is frequently a mess.
Consider what it would take to build a genuinely useful AI assistant for a mid-sized manufacturing company. The product information lives in one system. The customer data lives in another. The supply chain data is in a third, possibly partially in spreadsheets on a shared drive maintained by one person who has been there for twelve years. The ERP system the company uses is a decade old and has an API that was bolted on as an afterthought. The sales team keeps their best relationship intelligence in their personal email and their heads.
Getting AI to be genuinely useful in that environment isn’t a matter of subscribing to Copilot. It’s a substantial data engineering and systems integration project. The AI capability exists. The plumbing to connect it to the actual information it needs often doesn’t.
This is one reason why AI productivity gains are showing up so dramatically in certain sectors, particularly software development, professional services, and content-intensive work, and more slowly in others. The sectors where AI is moving fastest are the ones where work product is already digital, structured, and relatively accessible. The sectors where it’s moving slower often have the same fundamental capability needs but face a much harder integration problem first.
The second major friction is psychological and organizational rather than technical: people are genuinely bad at calibrating trust in AI systems, and organizations haven’t yet developed the norms and practices to help them do it well.
The failure mode goes in both directions. Some users over trust AI output, treating confidently generated text as accurate without verification, deploying AI-written analysis without checking the underlying reasoning, or automating decisions that actually required case-by-case human judgment. The consequences range from embarrassing to genuinely harmful depending on the stakes of the decision involved.
Other users under trust AI output in ways that eliminate the efficiency gains. They ask AI to draft something, then rewrite it from scratch because it didn’t capture their voice perfectly, taking longer than if they’d just written the original. They verify every AI-generated fact so thoroughly that the time saved on drafting is more than consumed by checking. They require human review of automated workflows at so many steps that the automation adds process overhead rather than reducing it.
Getting trust calibration right requires something that most organizations haven’t invested in: deliberate education about what current AI systems are actually good at, where they fail and how, and what appropriate oversight looks like for different use cases. The companies that are navigating this well tend to be the ones treating AI adoption as a change management exercise, not just a technology deployment. They’re running internal training not just on how to use the tools but on how to think about the tools.
One of the things that separates skilled AI users from unskilled ones is a kind of selective skepticism. It’s not blanket distrust and it’s not credulous acceptance. It’s a calibrated sense of where current models tend to be reliable and where they tend to drift.
Models are generally reliable on tasks involving structure, synthesis of information they have access to, and generation of fluent text in a given style. They are less reliable on precise factual claims, especially for anything recent or niche; on numerical reasoning involving complex multi-step calculations; and on anything requiring genuine awareness of context they haven’t been given.
A skilled practitioner develops something like a tacit feel for this. When an AI drafts a proposal and the structure and language are good but it cites a specific statistic, that’s the moment to verify. When it generates code that looks correct but handles an edge case in a way that seems off, that’s the moment to test carefully. The verification is targeted, not total. That’s what makes it sustainable.
The third friction is one that doesn’t get much coverage because it’s genuinely hard to write about in a way that’s interesting: AI adoption is creating real coordination problems inside organizations because different people and teams are adopting at wildly different rates and in ways that don’t necessarily interoperate.
Think about what happens when the marketing team has fully integrated AI into their content workflow, the sales team is using AI for outreach and CRM updates, and the legal team is still reviewing everything manually with no AI integration whatsoever. The marketing and sales teams are producing content and contracts at a pace that creates a bottleneck at legal review. The process optimization in two parts of the organization creates a new constraint somewhere else.
Or consider a team where half the members have become genuinely proficient AI users and half haven’t. The proficient half is producing significantly more output. The work distribution that made sense six months ago no longer reflects actual capacity. The team norms around who does what and how long things should take are quietly breaking down, and nobody has addressed it explicitly.
These aren’t technology problems. They’re management and organizational design problems that technology is surfacing. The organizations handling this best are the ones where leadership has recognized that uneven AI adoption isn’t just a training gap, it’s a structural issue that needs intentional coordination.
This is the question that hovers over every serious conversation about AI and work, and it deserves a direct answer rather than comfortable deflection. What does the human knowledge worker actually become as this operating system assembles itself around them?
The honest answer is: more themselves, for better and worse.
What that means in practice is that AI integration tends to amplify whatever someone brings to their work at a human level. The strategic thinker who was previously constrained by how long it took to gather and organize information now has that constraint largely removed. Their strategic thinking, which was always the scarce and valuable thing, can operate at a higher volume and with more supporting analysis than before. The person who was good at their job but not exceptional may find that AI assistance brings their output to a level previously accessible only to exceptional performers.
But the inverse is also true. The person whose value was primarily in being a fluent generator of structured outputs, the writer who produced serviceable but not distinctive prose, the analyst who ran standard models and produced standard reports, faces a harder question. When AI can perform the mechanical competence that defined their role reliably and at scale, what does their contribution become?
This isn’t a comfortable thing to say, but it’s worth saying plainly: the knowledge work roles that were primarily about proficient execution of well-defined tasks are genuinely under pressure. The roles that involve judgment, relationships, original thinking, ethical navigation, and the ability to work with ambiguous and contested information are not under the same pressure and may actually be enhanced by AI tools.
The transition between those two categories is where the real career and organizational anxiety lives. And it’s not an abstract future concern. It’s already playing out in hiring decisions, in the skills organizations are prioritizing, and in what junior roles in many industries actually look like compared to five years ago.
There’s a pattern that emerges when you look closely at the organizations genuinely pulling ahead on AI integration, as opposed to the ones generating impressive internal slide decks about their AI strategy while their actual workflows remain largely unchanged. The gap between those two groups is not about budget, access to technology, or even technical talent. It’s about a set of organizational choices that turn out to matter enormously.
The organizations getting real results started by mapping work, not by shopping for software. They asked: where does time actually go? Where do things slow down, break down, or get duplicated? Where is human judgment genuinely required, and where is a human in the loop mostly because nobody designed the process any other way?
That sounds obvious. It almost never happens in practice. The typical AI adoption story inside a large organization looks more like this: a vendor gives a compelling demo to senior leadership, a pilot gets approved, a tool gets rolled out to a team, people use it in the most surface-level way because nobody changed the underlying workflow, utilization numbers are gathered, the conclusion is “mixed results,” and the organization moves on to the next initiative.
The organizations actually getting ahead inverted this sequence. They did workflow analysis first, identified the specific moments where AI could remove a genuine bottleneck, and then selected tools that fit those moments. The tool selection was the last step, not the first. And because they understood the workflow before they touched the technology, they could actually measure whether things got better and why.
One large financial services firm went through this exercise and discovered that a significant fraction of their analyst time was being consumed by a single recurring task: compiling weekly market commentary from multiple internal and external sources into a standardized briefing format. The task required intelligence to do, in the sense that you needed to understand which information was relevant and how to frame it. But it didn’t require the specific intelligence of the people doing it. It was taking three hours a week from people whose judgment was needed elsewhere. A targeted AI workflow brought that to twenty minutes of human review on top of AI generation. Multiply that across a team and across a year and you have a meaningful reallocation of attention.
The lesson isn’t that the task was particularly glamorous to automate. The lesson is that they found it by looking at actual work rather than imagining use cases in a conference room.
This one sounds small and turns out to be large. The ability to work effectively with AI systems is a genuine skill, and it’s not evenly distributed. Some people pick it up intuitively and develop sophisticated working relationships with AI tools quickly. Many others use the same tools for months and extract a fraction of the available value, not because they’re less intelligent but because nobody taught them the fundamentals of how to interact with these systems effectively.
The organizations that are ahead have treated prompt literacy the way serious organizations once treated Excel literacy: as a baseline competency that you actively develop across your workforce, not something you assume people will figure out on their own.
What does that actually involve? The basics are teachable: how to give a model sufficient context, how to specify the format and tone you want in the output, how to break complex tasks into steps rather than asking for everything at once, how to critique and iterate on AI output rather than accepting the first result, how to recognize when a model is confabulating and what to do about it. None of this is mysterious. It just requires deliberate instruction and practice.
The more advanced layer involves understanding the specific failure modes of the tools your organization uses, developing team-level conventions for when AI assistance is appropriate and when it isn’t, and building shared libraries of effective prompts and workflows that teams can build on rather than everyone reinventing from scratch.
The ROI on this investment is genuinely high. An hour of prompt literacy training for a knowledge worker who uses AI tools daily can compound into dozens of hours of improved output over the following months. It’s one of the better workforce development investments available right now, and it’s still underutilized.
This is the hardest and most important thing, and it’s the one most organizations are avoiding because it’s genuinely difficult and politically complicated.
When AI is genuinely integrated into a workflow, the job changes. Not just the tasks, the job. The skills that matter shift. The outputs that are expected shift. The time allocation across different activities shifts. If you add AI tools to an existing role description and leave everything else the same, you’re either going to get underutilization (the person uses the tools occasionally for minor tasks and the role stays the same) or you’re going to get invisible work expansion (the person uses the tools to do more, the output volume increases, nobody formally acknowledges the change, and the person just works more).
The organizations doing this thoughtfully are having explicit conversations about what roles look like now that certain tasks can be handled at scale by AI. They’re rewriting job descriptions not to remove people but to be honest about where human contribution is most needed. They’re adjusting performance expectations to reflect the new baseline of what’s achievable. And they’re investing in developing the higher-order skills, judgment, communication, strategic thinking, client relationships, that become more important as the mechanical execution layer gets abstracted away.
This is uncomfortable work. It involves admitting that some roles as currently defined are going to change substantially, and that some people will need significant support to navigate that change. The organizations doing it anyway are building something more durable than the ones avoiding the conversation.
Most of the risk conversation around AI in the workplace focuses on either job displacement at a macro level or on spectacular failure modes like AI hallucinating facts in a legal brief. Both of those are real concerns. But there are subtler risks accumulating in the day-to-day reality of AI-integrated knowledge work that get much less attention and arguably deserve more.
When AI handles the execution of tasks that humans previously had to do manually, humans stop practicing those tasks. This is fine when the task was purely mechanical and there’s no reason to maintain the skill. But knowledge work involves a lot of tasks where the practice of doing them is how you build the deeper understanding that makes you effective at higher-level work.
Legal associates who spent years doing document review developed pattern recognition about how contracts are structured, where the risk tends to hide, what language signals problems. That pattern recognition came from the repetitive practice of reading hundreds of documents carefully. If AI handles document review from the start of a legal career, where does that pattern recognition come from?
Junior analysts who spent years building financial models in Excel developed intuitions about the mechanics of valuation, about which assumptions drive the answer, about where models tend to break. Those intuitions came from wrestling with the models directly. If AI generates the models, the intuitions may not develop.
This isn’t an argument against using AI for these tasks. It’s an argument for being deliberate about how skill development is structured in a world where AI handles the execution. The organizations and educational institutions thinking ahead are asking: if we’re not building skills through doing repetitive tasks anymore, how do we build them? That question doesn’t have a fully worked-out answer yet, but asking it is important.
Here’s something that’s easy to observe but hard to quantify: when large populations of knowledge workers use the same AI systems to help generate their output, the output starts to converge. The same structures, the same phrasings, the same ways of framing arguments, the same tonal register. The diversity of approaches that previously came from diverse people working independently through problems in their own way starts to compress.
This matters more in some domains than others. For genuinely routine outputs, standardization is probably fine or even desirable. But for the kind of work where original thinking and distinctive perspective are the point, intellectual homogenization is a real loss. The essay that sounds like everyone else’s essay. The strategy memo that recommends the things every strategy memo recommends. The pitch that hits all the expected notes without any of the unexpected ones.
The best individual practitioners are fighting this actively by using AI to handle structure and logistics while insisting on generating the actual ideas and distinctive angles themselves. But at an organizational and societal level, the homogenization pressure is real and worth monitoring.
When a human writes a report, there’s a clear author who can be held responsible for its accuracy and quality. When an AI generates a report and a human reviews it, the accountability picture is murkier. In practice, human review of AI output often isn’t as thorough as human generation would have been, because the output looks finished, which triggers a different cognitive mode than looking at a rough draft.
This creates a diffusion of accountability that can have real consequences. The analyst who would have caught an error if they’d built the model themselves doesn’t catch it when they’re reviewing an AI-generated output because the review process isn’t designed for that kind of critical interrogation. The lawyer who would have noticed the problematic clause if they’d read the contract from scratch misses it in AI-assisted review because the summary said everything was standard.
The organizations managing this well have built review processes specifically designed for AI output rather than assuming that normal human review is sufficient. They’ve made the accountability chain explicit: here is who is responsible for this output, and that responsibility includes genuinely interrogating the AI-generated content, not just cosigning it.
Step back from the workflows and the tools and the organizational challenges for a moment, and there’s a more fundamental question sitting underneath all of this that doesn’t get asked enough in business and technology coverage.
What is knowledge work actually for?
The standard answer involves productivity, output, economic value creation. And those things are real. But they’ve never been the complete picture. Knowledge work has also been a primary domain where people exercise agency, develop expertise, build identity, engage with problems that matter to them, and participate in something larger than their individual effort. The surgeon who finds genuine meaning in the skill of surgery, the teacher who finds purpose in the relationship with students, the researcher who cares deeply about the problem they’re trying to solve. Work has been, for a lot of people, a significant part of how they answer the question of what their life is about.
When AI takes over the mechanical execution of tasks, it raises the question of what’s left in the work that carries that kind of meaning. And the answer probably isn’t “nothing,” but it also probably isn’t automatically preserved without thought.
The people who seem to navigate this most healthily are the ones who’ve gotten clear, perhaps for the first time, about which parts of their work they actually valued intrinsically and which parts they were just doing because there was no other way to get to the parts they cared about. A researcher who discovered that they loved the analysis and the writing but found the data cleaning genuinely tedious might find AI integration deeply satisfying, because it removes the obstacle between them and the work they find meaningful. A different researcher who found that the patient work of data cleaning was itself satisfying in the way that craft work is satisfying might experience the same AI capability as a loss.
Neither response is wrong. But having clarity about which one you are is becoming more important, not less.
Predictions about specific AI capabilities and timelines are a good way to look foolish in print, so I’m going to largely avoid them. But some things about the trajectory of AI as an operating system for knowledge work seem reasonably stable.
The integration is going to deepen. The friction between AI capabilities and organizational systems is going to reduce as better tooling emerges and as organizations do the infrastructure work to make their data and processes AI-accessible. The agentic layer is going to become more capable and more reliable, which will expand the range of tasks that can be handed off with confidence.
The skills premium on judgment, relationship, and original thinking is going to increase. This has been directionally true for decades, as automation has consistently shifted labor demand from execution toward coordination and creativity. AI accelerates that trend substantially. The comfortable middle zone of skilled-but-routine knowledge work is going to narrow.
The organizations that invest now in understanding their own workflows deeply, in developing genuine AI literacy across their workforce, and in redesigning roles to reflect the new reality of what human contribution means will have structural advantages over the ones waiting to see how things shake out. Not because they’ll have better technology access, which will be roughly democratized, but because organizational capability is genuinely hard to build and takes time to develop.
And the question of what meaningful work looks like in a world where AI handles a substantial fraction of cognitive execution is going to become one of the more important cultural and philosophical questions of the next decade. It won’t be answered by technologists or by organizations. It’ll be worked out by individuals navigating their own relationships with their work and by the broader cultural conversations that follow.
Go back to that knowledge worker at the beginning of this piece, the one who’s spent forty minutes doing something a machine could do in four seconds. The upgrade waiting for them is genuine. The tools are here, they work, and the organizations and individuals using them well are experiencing real and meaningful changes in what they can accomplish and how they spend their time.
But an operating system upgrade isn’t something that happens to you. It requires you to actually understand the new system, migrate your workflows deliberately, accept that some familiar patterns are going to change, and invest in learning how to use the new capabilities well. It requires making real decisions about what you’re trying to preserve from the old way of working and what you’re genuinely glad to leave behind.
The technology is no longer the hard part. Understanding what you actually want from your work, building the organizational structures that let AI integration go well rather than poorly, and developing the judgment to use powerful tools wisely: those are the hard parts. They always were.
The question isn’t whether the operating system is getting upgraded. It is. The question is whether you’re going to be an active participant in that process or whether you’re going to click “remind me later” until one day the old version stops being supported entirely.